I9PB-43021 | Programmierkurs 2 Data Science (WS24/25)
Kursbeschreibung
Dieser Kurs bereitet die Studierenden auf fortgeschrittene Bereiche in Data Sciene vor und führt in einige der Werkzeuge und Begriffe ein, die häufig in Industrie und Forschung verwendet werden. Zu den Themen gehören: Lebenszyklus und Teamrollen innerhalb eines Data Science Projekts; Datenbeschaffung, Datenverständniss, Datenverarbeitung, Datenvisualisierung, Ergebnisspräsentation; Python-Programmierung und der Anwendung von grundlegenden Bibliotheken;
Lernziele: siehe Link zu Modulhandbuch
Dozent: Leonard Traeger
Vorlesungs und Praktikum (kombiniert): Montags um 12-13:30 u. 14:15-15:50 Uhr; Vorlesungen werden nicht aufgezeichnet
Kurswebsite: http://leotraeg.github.io/me/I9PB-43021.html
Kurssprache: Folien (Englisch), Vorlesung (Deutsch), Mündliche Prüfung (wahlweise Deutsch/Englisch)
GitHub: https://github.com/leotraeg/FHDTM-P2DS-WS2425
Ilias (Umfragen, Artefakte, Q&A): https://www.ilias.fh-dortmund.de/ilias/goto_ilias-fhdo_crs_1334419.html
Sprechstunde: über Kontakt buchbar (online)
Raum: C.2.32 (in Präsenzlehre) / oder WebEx-Link (Online) siehe Zeitplan in Spalte "Ort"
Format
Vorlesung: Die Vorlesung vermittelt theoretische Konzepte und stellt Werkzeuge der Programmierung im Bereich Data Science vor (passiv). Nach Abschluss und Zusammenfassung eines Konzepts sind die Kursteilnehmer*innen gefragt, Erlerntes eigenständig, jedoch mit Hilfestellungen, konzeptionell oder in der eigenen Programmierumgebung auf ein Anwendungsbeispiel zu übertragen (aktiv). Lernziele werden zu Beginn einer Vorlesung formuliert. Übungsaufgaben sind in den Vorlesungsfolien als Training oder Think-Pair-Share gekennzeichnet.
Logistik: Der Vorlesungsort findet i.d.R. wöchentlich und in Präsenz (P) statt. Bei geigneten Lehrinhalten, überschaubarer Teilnehmeranzahl und Teilnehmerabsprache kann die Vorlesung mit einer einwöchigen Vorlaufzeit in ein Online-Format (O) wechseln. In keiner der Formate wird die Vorlesung aufgezeichnet.
Artefakte: Die Abgabe von Praktika und Projektmeilensteinen findet ausschließlich digital über Ilias zum Tagesende (23:59 Uhr) des Stichtags statt. Bitte treten Sie dem Kurs bei. Die verbindlichen Abgabefristen können sie unter "02 Artefakte" einsehen.
Praktikum: Das Praktikum kann vorzugsweise zu zweit oder inviduell bearbeitet werden. Es ist in zwei Abschnitte unterteilt, befasst Lerninhalte von der Vorlesung und ist jeweils über drei Wochen zu bearbeiten. Die Aufgaben unterstützen die Studierenden beim konzeptionellen Verständniss und notwendiger Programmierkenntnisse der verwendeten Bibliotheken innerhalb des Data Science Projekts. Beide Praktikumsabschnitte sind freiweillig und können jeweils mit bis zu 8% (Gesamt 16%) an zusätzlichen Prozentpunkten zur Aufrechnungen der Modulnote beitragen.
Projekt: Das Projekt verläuft parallel zum gesamten Semester und ist innerhalb selbst bestimmender Teams (à vier Teilnehmenden) zu bearbeiten. Ziel ist die Durchführung eines praktischen Data Science Projekts auf Grundlage eines Teambestimmenden Datensatzes. Das Projekt darf sich mit anderen Forschungsarbeiten überschneiden, aber nicht mit einem anderen Modul. Aufbauende Forschungsarbeiten, an welchen Sie oder Ihre Teamkollegen arbeiten, oder mit Ihrer Arbeit zu tun haben, sind sogar erwünscht. Bitte klären Sie in diesem Fall frühzeitig ab, dass alle Gruppenmitglieder Zugriff auf ein Data Snapshot (.csv, .json, .xml, o.ä.) erhalten. Ich hoffe, dieser Kurs hilft Ihnen bei der Lösung von Data-Science-Aufgaben, an denen Sie bereits interessiert sind. Ihre Projektarbeit muss jedoch Ihre eigene sein und nicht die Ihrer (Arbeits-)Kollegen oder höhersemestriger Kommilitonen. Das Projekt enthält eine programmatische Umsetzungskomponente. Beachten Sie, dass Data Science Projekte anspruchsvoll und unsicher im Ausgang sind, und es vollkommen in Ordnung ist, wenn das Projekt keine positiven Ergebnisse (Erkentnisse) liefert. Beispiele für Themenbereiche sind die Auswertung von Finanzdaten, medizinische/klinische Anwendungen, Geschäftsanwendungen, soziale Netzwerke, usw. Hier sind ein paar mögliche Quellen für Datensätze, die Ihnen den Einstieg erleichtern könnten:
Um einen erfolgreichen Rahmen sicherzustellen, ist das Projekt in drei Meilensteine aufgeteilt: Meilenstein I (Bericht mit nicht mehr als 2 Seiten):
Beispiel I: Gesundheit wegen steigender Adipositas-Rate Quelle.
Beispiel II: Fußballspieler, da Deutscher Fußball-Bund (DFB) Qualität und Transparenz der Spielvermittlung und -beratung nachhaltig erhöhen will Quelle.
Beispiel I: Framework OSEMN und Komponente (O) Obtain: 50% - Datensatz existiert (wahrscheinlich / in der gewünschten Form) noch nicht und wird mittels Web-Scraping extrahiert.
Beispiel II: Framework KDD und Komponente Preprocessing: 50% - Datensatz existiert in Rohformat, benötigt jedoch voraussichtlich umfassendes Data Preprocessing.
Bitte beachten Sie unbedingt, dass keine Data Mining Methoden wie supervised (classification oder regression) oder unsupervised models (clustering) inklusive neural networks in diesem Modul behandelt werden. Bitte nullen Sie daher den Arbeitsaufwand dieser Komponente in dem gewählten Framework.
Wenn Sie Hilfe bei der Auswahl einer Gruppe, Projektdomäne oder Data Science Life Cycle Frameworks benötigen, vereinbaren Sie bitte einen Termin in meiner Sprechstunde oder senden Sie mir eine Email. Sie werden ihre Projektdomäne gemeinsam den anderen Studierenden in Woche #4 (ca. 2 Minuten und nur über die Tonspur) vorstellen.
Meilenstein II (Bericht in Form eines .ipynb Python Skripts):
Meilenstein II und der Zeitraum zur Prüfungsregistrierung liegen nah beieinander. Bitte kommunizieren Sie daher frühzeitig ihre Erwartungen an das Projekt mit ihrem Team, um etwaige Konflikte frühzeitig aus dem Weg zu räumen. Für Hilfestellungen bitte ich Sie einen Termin in meiner Sprechstunde zu buchen. Meilenstein III.1 (A2 Poster):
Notenzusammensetzung; Änderungen vorbehalten
| Artefakt | Max. Punkte |
|---|---|
| Ilias Forum Beitrag oder Kommentar | 0,66% |
| Praktikum I | 8% |
| Praktikum II | 8% |
| Projekt Meilenstein I | 5% |
| Projekt Meilenstein II | 10% |
| Projekt Meilenstein III.1 und das Projekt Meilenstein III.2 |
35% |
| Mündliche Prüfung über Vorlesungsinhalte | 50% |
Skala; Änderungen vorbehalten
| Punkte | Note |
|---|---|
| 116,66 - 94,9 % | 1,0 |
| <94,9 - 89,5 % | 1,3 |
| <89,5 - 84,3 % | 1,7 |
| <84,3 - 79,0 % | 2,0 |
| <79,0 - 73,7 % | 2,3 |
| <73,7 - 68,2 % | 2,7 |
| <68,2 - 63,1 % | 3,0 |
| <63,1 - 57,9 % | 3,3 |
| <57,9 - 52,6 % | 3,7 |
| <52,6 - 50,0 % | 4,0 |
| < 50,0 % | n.b. |
Projekte

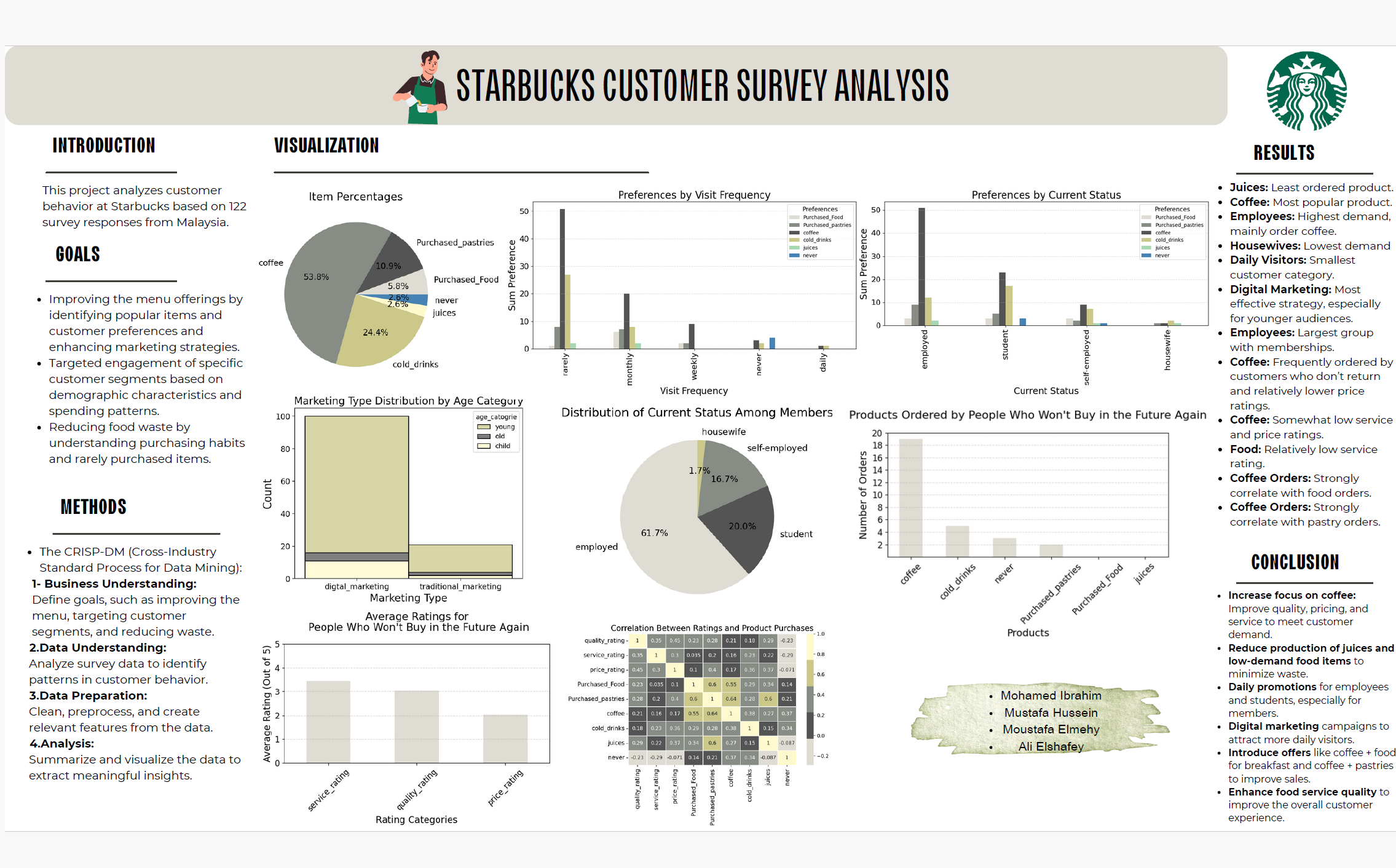

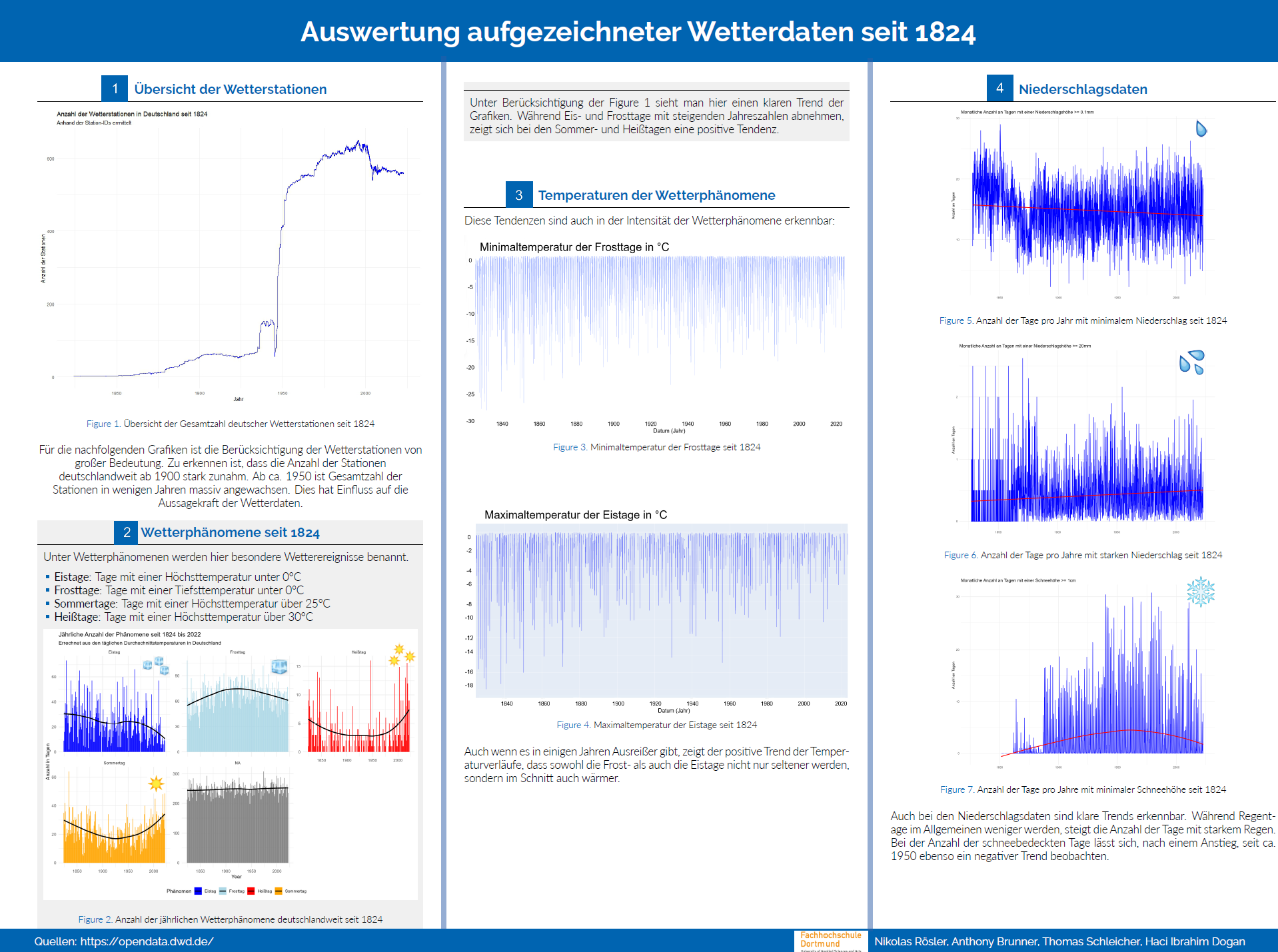

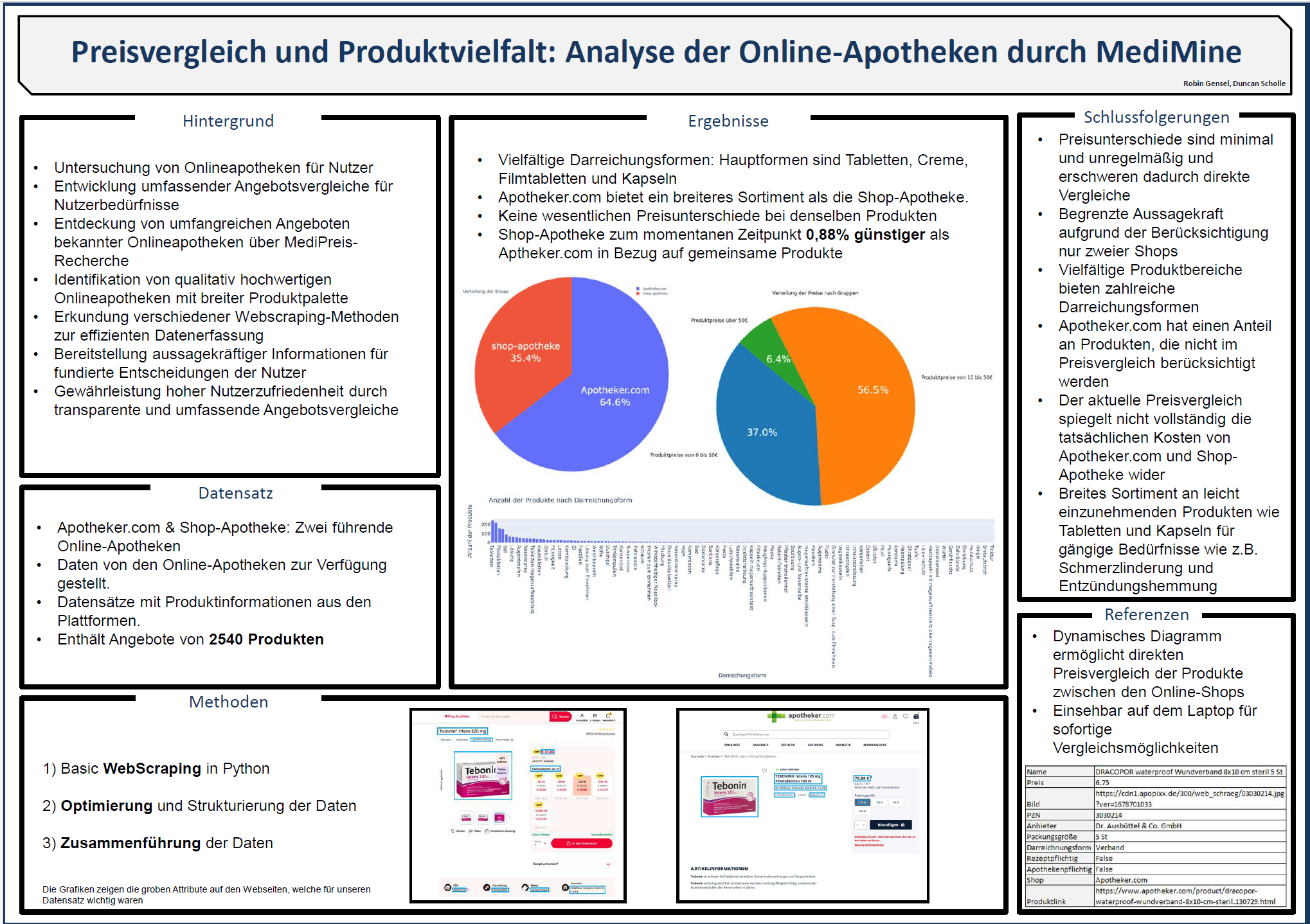
Literatur Empfehlungen:
Zeitplan
| Datum | Woche | Zusammenfassung | Details | Ort | Artefakte | Literatur |
|---|---|---|---|---|---|---|
| 23.09.24 | 1 | Einführung; Python I (Intro) | Einführung Data Science, Kurslogistik, Python, Jupyter and Colab Notebooks, Basic Data Types, Random Numbers, String methods | P | "Python Data Analytics With Pandas, NumPy, and Matplotlib": Seiten 19-35 ohne Kapitel "Model Validation", "Predictive Modeling", "Deployment" | |
| 30.09.24 | 2 | Python II | Data Science Life Cycle, Data Literacy, Ethics, Comparison and Logical Operators, Control Statements, Containers (Lists, Dictionaries, Sets, Tuples), Functions, Functional Programming incl. Map, Filter, Reduce, List Comprehensions, Übersicht zu Anforderungen an Projekt insb. Meilenstein I: Data Science Framework | P | Teams formiert zu diesem Stichtag (Ilias Gruppe eingetreten) und per Mail an leonard.traeger@fh-dortmund.de von einem Gruppenmitglied bestätigt | |
| 07.10.24 | 3 | Python III + Data Formats | Imperative and Declarative Paradigm, Object-Oriented Programming incl. Constructor, Destructor, Decorator annotated and regular Class Methods, and Inheritance; CSV, JSON, and XML as Common Data Formats | O | Abgabefrist Projekt Meilenstein I Veröffentlichung Praktikum I |
Python OOP Tutorials by Corey Schafer - Working with Classes: https://youtube.com/playlist?list=PL-osiE80TeTsqhIuOqKhwlXsIBIdSeYtc&si=ClE0TjUvd0DKzKTZSlides by Charles Severance: https://www.py4e.com/lessons/Objects# |
| 14.10.24 | 4 | Python NumPy + Open&Tidy Data | Containers versus NumPy, Datatypes, Booleans, Comparison, Indexing / Slicing, Reshape, Copy(), Vectorization (Ufuncs), SciPy, Aggregation, Sorting, Broadcasting | O | VanderPlas, J., "Python Data Science Handbook", O'Reilly, 2017: Seiten 59-124 cs231n.github.io/python-NumPy-tutorial/ jbhender.github.io/Stats507/F21/slides/NumPy.slides.html docs.scipy.org/doc/scipy/reference/ |
|
| 21.10.24 | 5 | Keine Vorlesung | Vorlesungsfrei | |||
| 28.10.24 | 6 | Python Pandas I + Web-Scraping | Data Series and Frames, I/O: Read and Parse Different Data Formats, Viewing Data, Indexing, Data Reduction (Selection and Deletion), Data Masking, Viewing Meta Data, Exkurs I: Datenbeschaffung (Demo Web Scraping with BeautifulSoup) | P | Abgabefrist Praktikum I | pandas.pydata.org/Pandas_Cheat_Sheet.pdf https://jakevdp.github.io/PythonDataScienceHandbook/03.01-introducing-pandas-objects.html |
| 04.11.24 | 7 | Python Pandas II.1 | NumPy and Pandas, Data Preprocessing (Data Reduction, Data Cleaning, Data Integration, Data Transformation), Exkurs II: Datenverständniss, Datenverarbeitung (Demo Data Preprocessing with Pandas) | P | Last Call: Hilfestellung Teamprojekt und Datensatz | |
| 11.11.24 | 8 | Keine Vorlesung | ||||
| 18.11.24 | 9 | Keine Vorlesung | Vorlesungsfrei (Blockwoche 2) | |||
| 25.11.24 | 10 | Python Pandas II.2 | O | Abgabefrist Projekt Meilenstein II | ||
| 02.12.24 | 11 | Python Visualization | Simple Plots, Text and Annotation, Color, Plotting with NumPy and pandas, Data Summary Plots, Meta Data Plots, Exkurs III: Visualisierung und Präsentierung (Demo Plotting) | O | Veröffentlichung Praktikum II | |
| 09.12.24 | 12 | R I | Grundlagen R: Vektorisierte Operationen, Vektoren, Listen, Matrizen, Data Frames, Funktionen und Packages | O | Zeitraumende Prüfungsregistrierung | https://r4ds.hadley.nz/ https://www.phonetik.uni-muenchen.de/~jmh/lehre/basic_r/_book/index.html R Cheatsheet: https://www.rstudio.com/wp-content/uploads/2015/02/data-wrangling-cheatsheet.pdf |
| 16.12.24 | 13 | R II | Dataframes, Funktionen, Transformationen, Visualisierungen | O | ||
| 23.12.24 | 14 | Keine Vorlesung | Vorlesungsfrei (Ferien) | Abgabefrist Praktikum II | ||
| 30.12.24 | 15 | Keine Vorlesung | Vorlesungsfrei (Ferien) | |||
| 06.01.25 | 16 | Präsentation Projektposter | Studierende präsentieren ihr Projekt untereinander in der ersten Stunde; In der zweiten Stunde findet eine bewertete Präsentation statt (Teamprojekt à 10 Minuten) | P | Präsentation Projekt Meilenstein III.1 Frühzeitige Abgabe (tbd.) falls Posterdruck über die Hochschule erwünscht. | |
| 13.01.25 | 17 | Recap | Kurszusammenfassung und Prüfungsvorbereitung | O | Abgabefrist Projekt Meilenstein III.2 Heute um 13:00 Uhr! |
|
| tbd. | 18 | Mündliche Prüfungen | 1:1 Prüfungstermine Beginn Prüfungszeitraum Bitte unter Ilias drei zeitliche Präferenzen bis zu dieser Woche angeben, sodass zum Stichtag die individuelle Prüfungszeit automatisiert zugewiesen wird. |
O |
Voraussetzungen
Grundkentnisse in Algorithmen, Datenstrukturen und in der objektorientieren Programmierung von Vorteil.
Hardware:
Software:
Kontakt
Onlinetermin bitte über Meetergo buchen oder leonard.traeger@fh-dortmund.de kontaktieren.